

-
多中心临床数据的快速检索系统
摘 要 临床数据共享平台是我国医疗信息化发展的重要方向,在当今医疗数据呈几何级增长的环境下,多中心海量的临床数据如何管理、共享、并有效地查询和检索是一项重要的课题.该系统使用HL7CDA XML作为描述电子病历的标准,采用关系型一XML混合数据库提供索引和XQuery查询工具.同时为了提高查询效率和并发性能,使用了BerkeleyDB作为Key-Value存储的数据层,并架设了Memcached作为查询数据的缓存层,增强了整体系统的可用性,最终形成了一个标准、通用、高效的临床数据共享平台.
关键词 HL7;CDA;多中心;临床数据共享
我国当前新医改的三大信息化要点明确提出,要建立居民健康信息档案、医疗信息共享平台及区域医疗体系.经过医疗行业多年的建设和发展,目前各大医院和医疗单位已逐渐形成了以医院管理信息系统HIS、电子病历EMR、实验室信息管理系统LIS、医学影像系统PACS以及放射信息管理系统RIS为主要应用的综合性信息系统.随着医疗数据规模呈几何级数增长,为了有效存储和利用相关数据,推进基于区域医疗体系的更高层次的医疗信息共享,尤其是医疗信息中的临床数据,迫切需要建立多中心、网络化、大样本的共享平台进行有效管理,以便为医院的业务提供支撑,同时满足对临床数据进行研究的需要.
我们目前所参与的卫生部重大项目“心脏瓣膜病规范化外科治疗的研究”就是要建设一个典型的多中心临床数据共享平台,并用于心脏瓣膜病外科手术治疗的标准化临床数据研究.该项目通过我国6家最具规模的心脏外科中心(上海长海医院、中国人民解放军总医院、北京阜外心血管病医院、北京安贞医院、上海中山医院、广东省人民医院)的合作,以多家医院近10年来的电子病历(electronic medicalrecord,EMR)信息为基础,初步建立我国瓣膜病外科治疗数据库和信息共享平台.以此为下一步在全国范围内建立类似于刚芯National,Database National,Adult CardiacSurgical Database的大型医疗数据库和信息平台提供经验.该项目所设计的多中心系统面临最主要的问题有如下两点:
1.多中心导致的数据规范问题
临床数据中的电子病历数据是整个医疗过程中最为基本同时也最为多样的信息要素.由于患者医疗信息数据类型各异,且内容复杂,且由于医疗机构各自的信息化发展程度不同,医疗信息表示方式不同,电子病历的模式规范和数据标准也各不相同.这对于多中心的医疗数据共享平台而言,是必须跨越的一道障碍.
2.海量医疗数据造成的查询效率问题一份完整的电子病历是患者自入院到出院的就诊过程的全程记录.电子病历应涵盖的内容包括:病人基本信息;病程记录;护理记录;检查检验记录(各种影像图像等);以及手术记录等.因此一份电子病历的信息容量可以达到数兆至数十兆.本项目的多中心数据共享平台将容纳几万至几十万份电子病历,如何在海量的临床数据中进行有效快速的查询和分析,是一个重要的课题.
1系统设计
1.1系统设计目标
1.使用通用的数据标准,设计含有语义信息的病历文档格式,支持符合国际标准的电子病历文档与现有临床文档的交互接口.
2.系统应当具有很好的适应性,容易满足各种医疗单位的设计需求,而无需对标准进行扩展.
3.开发一个用户界面友好的Web页面方便医师用浏览器进行数据录入、增删、综合查询以及导出.
4.设计一个独立的业务层,与底层存储机制无关.
5.系统应当具有很好的可用性,需要进行新型的数据库设计,对海量病历数据的查询具有良好的性能.
1.2临床数据的通用标准
为解决数据规范问题,在项目中我们使用了国际通行的临床文档标准HL7 CDAE¨.为实现跨机构的信息共享和信息交换,HL7(Health Level 7)是20世纪80年代末发展起来的医学信息交换协议.2000年10月,HL7组织发布了第1个基于XML的医疗行业的临床文档结构(clinical document architecture,CDA)标准.CDA
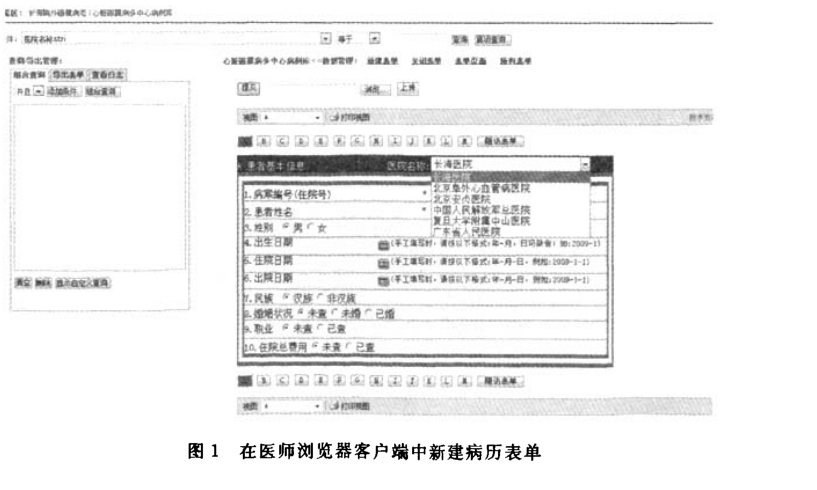
以数据交换为目的,描述临床文档的结构和语义,是HL7标准集的一部分.由于HL7规范过于复杂,因此目前国外的医疗机构大多采用了较为简洁的CDA作为电子病历的标准.符合CDA标准的XML病历表单数据项复杂,虽然具备一定的语义信息,但是由医务人员直接设计、添加和修改是相当困难的.在2003年2月的HIMSS会议上,Microsoft发布了一个InfoPath2003 CDA演示2.0版,以XML表单为基础,与HL7CDA和消息标准完全兼容,很好地解决了这个问题.它通过动态表单收集所需的信息,能够帮助用户完成XML表单文档的结构化设计和编辑比.在本项目中我们使用了InfoPath 2007作为XML病历表单的设计和输入工具,文档在设计和执行上与XML CDA的架构完全一致,能够向最终用户提供一个标准化的、清晰直接的电子病历文档编辑界面.标准病历文档既能够被机器处理,也能够被人阅读,易于检索和使用.此外我们还设计了内嵌在Web容器中的InfoPath表单,使得最终用户可以方便地使用浏览器查询修改病历表单.图1就是系统中医师在浏览器中新建病历表单.
1.3数据层设计
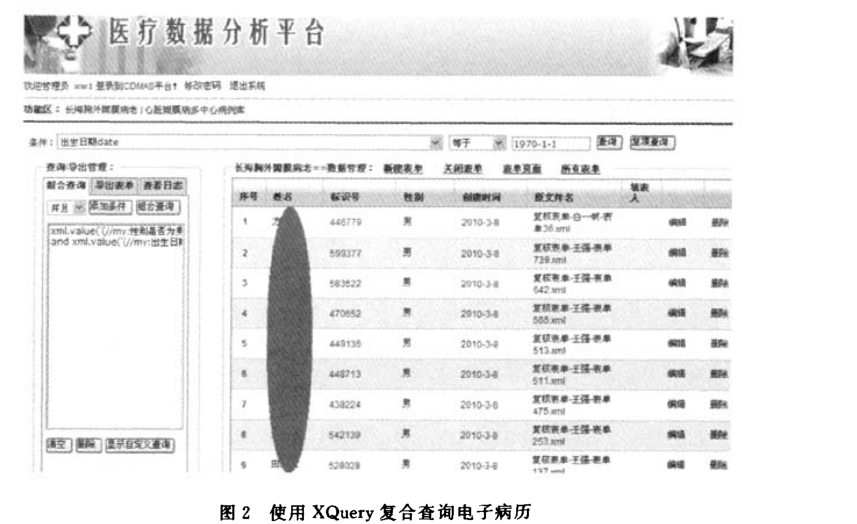
为了提供XML的数据索引和检索功能,我们采用了SQL Server 2005做为系统的底层数据库,它支持XML作为数据列,是XML和关系型混合的数据库服务器.在数据库中存储两类不同的数据,一种是普通的关系型数据,XML数据列用于存储病历CDA XML数据.由于电子病历查询的是XML中各项节点Value,我们在XML列上建立Nodes型索引以提高查询效率.关系型数据项在系统中数目很少,用于存储用户信息以及系统操作记录,而XML数据项很多,病历中几乎所有数据(除去文件附件部分,例如图片或照片等,该部分存储在
Sharepoint文件服务器中)均存储在XML中.对于XML数据,我们采用XQuery+SQL的混合模式查询.图2是在系统中实现的复合查询示意:
 1.4业务层设计
1.4业务层设计
Web Service基于XML文档进行服务描述、服务请求和反馈结果,可以在|nternet上通过HTTP
协议进行传递,与平台和操作系统无关,因此以Web服务做为业务层核心模块是非常适合的.在我们的系统中WebService模块包装所有的业务需求,为客户端提供各种功能函数,主要完成身份认证确认、记录日志、管理用户、新建病历模板、编辑病历数据、对提交的病历XML数据提供HL7 CDA的验证和解析、为客户端提供统一的查询函数以及提供病历数据的批量导入导出功能并提供异地备份函数.
1.5 系统框架
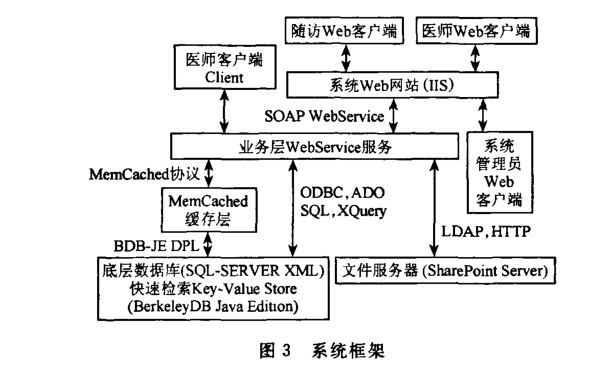
根据系统设计目标,我们使用c/s,B/S混合结构,用Client和Browser分别实现InfoPath客户端用于处理XML病历文档,业务逻辑全部封装在服务器端.客户端与服务端之间的接口采用标准协议通信,我们使用WebService提供接口应用函数,服务端对所有的数据库操作和SharePoint文件服务器操作进行封装,确保不同系统平台上的通用性.系统中各模块如下:
1.各种权限的客户端,包括系统管理员客户端、医师客户端(管理病历表单)以及随访人员客户端.
2.病历系统Web服务器,用于提供医师Browser客户端所访问的Web页面,并和WebService服务端通信,完成业务需求.
3.病历系统WebService服务端,是业务层核心模块,负责与所有客户层模块通信,封装所有业务需求,并和底层的数据库服务器和文件服务器通信.
4.底层数据库服务端,用于存储所有的病历信息和业务信息,提供索引和查询.
5.文件服务器端,采用SharePoint Server,用于InfoPath电子病历文件的Web解析和存储,存储所有病历表单的文件附件,并备份所有病历信息和业务信息.
6.缓存层,用于提高并发效率和数据访问速度.具体的系统框架如图3所示:
 2海量数据的查询设计
2海量数据的查询设计
作为全国范围内的多中心电子病历数据平台,对于海量数据的存储可扩展性以及多并发用户查询效率有很高的要求,只采用常规的XML数据库的索引和XQuery检索技术满足不了系统性能要求.因此我们设计了基于Key-Value存储的高效辅助数据层,并设计了数据访问的中间缓存层.
2.1基于Key-Value存储的高效数据层
根据分布式领域的CAP(consistency,availability,partition tolerance)理论,一个分布式系统不可能同时满足一致性、可用性和分区容错性这3个需求,最多只能同时满足2个.大部分Web应用基于可用性的考虑,都使用了轻量级的Key-Value数据库,在目前的云计算、云存储的大环境中,这些系统发挥了越来越重要的作用.例如An'k3zon的Dynamo,SimpleDB,
Google的BigTable,Mixi使用的Tokyo Cabinet等等.分布式Key-Value系统提供弱一致性的支持,或者支持“最终一致性(eventually consistent)”,用户B在某个时间点后会看到用户A的修改信息.在系统中,我们采用了BekerleyDB JavaEdition(BDB-JE)作为数据层.Berkeley DB是历史悠久的嵌入式数据库系统,以Key-Value存储为基础,用高效的方式支持数千并发访问和最大256TB的存储量(单库).由于我们在多中心的数据库层需要提供跨平台的特性,因此选用了BDB的Java实现BDB-JE.我们使用了BDB-JE的直接持久化层DPL(direct
persistent layer),将病历文档的XML数据扁平化后,以病历编号作为Primary Key,将需要查询的表单域值作为Secondary Key,建立B+树索引,大幅提高了数据访问的速度.相较于SQLServer的XQuery查询速度,BDB-JE查询速度提高了20~30倍.表1是单线程情况下2种方法对不同容量数据库平均访问时间的比较,对病历数据使用的是相同语义的查询.在多线程(多并发)情况下,BDB-JE因为没有强一致性的限定,性能更加优于SQLServer的XQuery查询.
 2.2分布式的缓存设计
2.2分布式的缓存设计
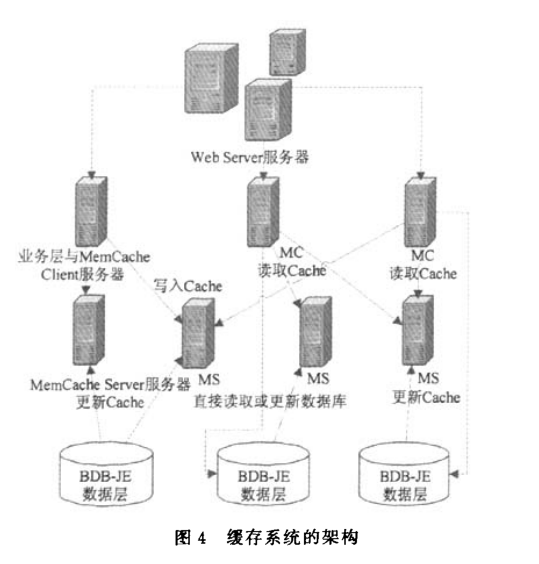
为减少数据库的读取负担,提高数据读取速度,我们在业务层和数据层之间增加了一个cache缓存层.由于我们系统中数据的分布式特点,且由于数据读取速度的要求,缓存层必须建立在内存上,而单台服务器的内存大小受限,不可能做到硬盘的T级容量水平,因此我们考虑采用分布式的cache层.在系统中我们采用了开源项目Memcachedt 4。,它是一个基于内存实现的分布式Key-Value缓存系统,能够缓存各种DB,API访问结果,目前很多著名的网站比如Wikipedia,Flickr,Twitter以及我国的新浪等,都使用了该缓存系统,有效地缓解了数据库的访问压力,提高了系统的并发访问性能.Memcached处理的对象是Key—Value对,由2个核心组件组成:Memcaehed Client(MC)和MemcachedServer(MS),在一个查询中,MC先通过计算key的Hash值来确定所处的MS位置.当MS确定后,客户端就会发送一个查询请求给对应的MS,让它来查找确切的数据.在本系统中,MC端直接实现在WebService业务层上,在MC端把所有对BDB-JE进行的Select类型的查询Query进行相应Hash计算得出一个数据Key,用这个KPj,对MS查询,如果没有查询到,就说明还没有写入到缓存中,那么直接访问BDB-JE查询到数据后写入MS中.同时,在BDB-JE DPL层上设立触发器机制,一旦有数据Update或者Insert进来就对MS进行同步更新,以供用户有可能的访问.缓存策略采用LRU(最近最少使用),当MS的Hash表满了之后,新的插入数据会替代老的最近最少使用的数据.同时会考虑每个Key-Value对的有效时限,超过有效时限也同样会清除,Key—Value对存储有效时限是在MC端由业务层设置并作为参数传给MS的.图4是系统中Memcached缓存系统的架构设计.
 3
3
结 论
临床电子病历的数据形式复杂多样,多中心的海量临床数据采用传统数据库进行存储和查询存在很多问题,本文采用符合国际标准HL7 CDA的XML数据格式描述病历信息,基于Key—Value存储的架构构建了BDB-JE作为数据的快速检索层,以及Memcached作为分布式的数据读取缓存层,大大提高了查询性能.本文的临床数据共享平台由于标准化和通用化的设计,以及数据查询的高效率,目前已应用在多个医院科室的不同临床数据库.
.jpg)




